How I Use LLMs for Data Harmonization: A Strategic, Limited Approach
A technical walkthrough of how I used LLMs strategically to improve name harmonization for clinical trial sponsors while minimizing non-determinism.
I recently built a data harmonization pipeline for a biotech intelligence product using a combination of rule-based harmonization and LLM inference (OpenAI’s GPT-4o). While LLMs can be powerful tools, I’ll discuss how I approach integrating them into data pipelines, and my less is more approach to using LLMs in data engineering.
Project Background
Regulatory filings required in biotech and pharma can provide a lot of insight both into what individual companies are doing and what the development landscape looks like as a whole. Many of the competitive intelligence tools sold for hundreds of thousands of dollars a year are actually built on top of freely available regulatory data from sources such as USPTO, FDA, SEC, and NIH. The challenge is pulling these sources together in a meaningful way. This project is part of a large RxDataLab effort to unify regulatory data in a way that is easy to search and understand.
Sponsor Names and the Clinical Trial Registry
One of the best ways to get a view of a company’s drug development pipeline is to look at their active clinical trials. ClinicalTrials.gov is a public registry of clinical studies conducted around the world, maintained by the National Library of Medicine at the National Institutes of Health. This database provides transparency into ongoing and completed clinical research, providing a vital lens into active pharma research projects and timelines.
Trials are identified by a National Clinical Trial (NCT) ID and associated with lead sponsors and collaborators. Unfortunately, sponsor naming is messy, as there isn’t a standard mandating a name format.
For example, a search for Medtronic reveals different naming styles and business units:
- Medtronic
- Medtronic - MITG
- Medtronic Diabetes
- Medtronic Cardiovascular
- Medtronic Spinal and Biologics
Other companies use country-level subsidiaries:
- Incyte Corporation
- Incyte Biosciences Japan GK
- Incyte Biosciences International Sàrl
And many large firms use names of acquired or wholly-owned subsidiaries:
- Merck Sharp & Dohme LLC
- Acceleron Pharma, Inc., a wholly owned subsidiary of Merck
- Prometheus Biosciences, Inc., a subsidiary of Merck
- ArQule, Inc., a subsidiary of Merck Sharp & Dohme LLC
This is all on top of the typical company name complexity of acquisitions, re-branding, etc. Since this project involves linking across separate databases, for example SEC filings and the FDA Orange Book, it is vital to develop a key to link across the datasets in a standard and meaningful way.
Harmonization and Choosing a Central Key
Data harmonization refers to the process of combining and transforming data into a meaningful format. Harmonization can occur across datasets or within a dataset. The definition of “meaningful” is relative to your goals. For this project, I am targeting both internal harmonization for company names and external harmonization with SEC and FDA data. For internal harmonization, I need the ability to gather studies by company identity, irrespective of naming/spelling differences, business units, or mergers and acquisitions. A search for “Medtronic” should return studies assigned to “Medtronic Cardiovascular” and “Medtronic plc”, while a search for “Johnson & Johnson” should also return studies sponsored by their subsidiary Janssen Pharmaceuticals. For external harmonization, the same searches should return financial disclosures from the SEC and approved drugs from FDA. Both types of harmonization require a common term or reference. Since I’m designing a database, I’ll call this common reference a key.

There are a lot of possible keys you can use. I like to consider using a key that will provide the most leverage with the datasets I am including. A high leverage key would be something that might already exist in one or more of the databases, or a key that exists in one database and but links to many others.
In this case, the ClinicalTrials database was the primary database, but I chose the SEC-assigned Central Index Key (CIK), as the high leverage key I would link to. The benefits of using a CIK:
- Standardization: Name changes (e.g., Tempus -> Tempus AI) typically don’t affect the CIK
- Reliability: Failing to file disclosures with SEC is more serious than being late to update Clinical Trial registries, so data is more likely to be timely and reliable
- Enrichment potential: The SEC has valuable information I can use to enrich the company data, such as address, officers, name history, stock ticker (which can be used to link to still more databases), etc.
The last point about enrichment potential makes CIK a particularly high leverage key. It not only provides a legal “ground truth” for company names but it maps to equity markets via stock ticker, and provides high value business information about company provenance and history, canonical names, and financial disclosures.
CIK’s also cover many private companies, since it is generated for any company required to make SEC disclosures, which includes fundraising.
This isn’t to say using CIK’s is perfect—companies can have multiple CIK’s and it can be especially complex with holding companies or foreign companies issuing stock under an ADR. Also, while all public companies and most private companies have or will have a CIK, some won’t. This slightly complicates my database schema but I won’t cover the details here.
Matching Sponsors to CIKs
For this initial development effort, I focused on companies (excluding academic and government studies) with phase 2 or 3 trials estimated to end in the next 18 months. So essentially (in SQL):
SELECT DISTINCT sponsor_name FROM sponsors…
This left over 3,000 distinct sponsor names. The SEC provides an API for fuzzy matching on company name, but it isn’t quite suited for programmatic use, and in my experience it requires significant curation and manual checking. This is clearly achievable manually, but very time consuming. I considered three options:
- Hire freelancers expensive, inconsistent, and slow.
- Use fuzzy string matching + SEC API – better, but prone to noise.
- Use a large language model (LLM) – scalable, but potentially unreliable.
On its face, mapping company_name -> CIK seems like a fantastic use case for an LLM. Unfortunately, my manual tests to map sponsor names to CIKs were unreliable and prone to hallucinations.
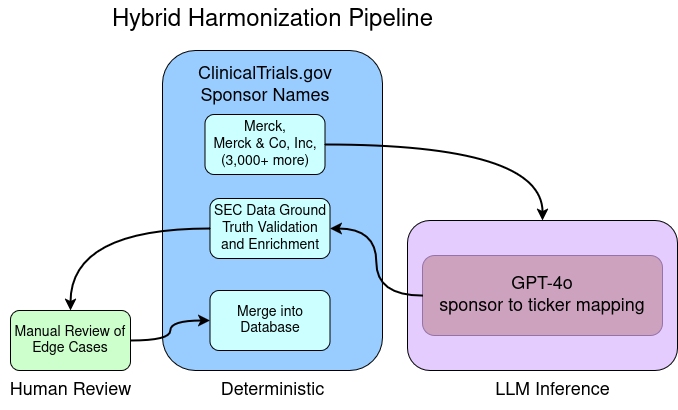
However, company_name -> stock ticker proved far more reliable, likely due to broader exposure to tickers and stock commentary in training data. Once I had this mapping, I could use official SEC data to programmatically map ticker to CIK and the name registered with the SEC. So the rough pipeline outline would be:
- Preprocess sponsor names (strip “Inc.”, lowercase, etc.)
- Use GPT-4o to map sponsor name → ticker
- Map ticker → SEC company data (including CIK)

The programmatic mapping after LLM inference also provided a key point to validate my work and limit the risk of hallucinations slipping into my foundational data set.
Limiting Blast Radius when Using LLMs in Data Pipelines
The foundational database needs to be very high quality, since all inference and analysis tools are built on top of it. This harmonization pipeline will also be run whenever data is updated (weekly), potentially amplifying errors or inconsistencies introduced early. Ensuring reliability requires testing and a high degree of determinism (A -> B near 100% of the time). LLMs are notoriously non-deterministic and context dependent, so I am very reluctant to use LLMs in data engineering pipelines. To contain the risk here, I built in a conservative validation step that forces a human to make decisions and approve new or unclear mappings.
Here’s how I approached that:
- LLM outputs a structure that provides the answer, a confidence score (low, medium, high), and notes
{
"input_name": "Vertex Pharmaceuticals Incorporated",
"ticker": "VRTX",
"confidence": "high",
"notes": ""
}
- After inference, my pipeline uses the SEC export of CIK, ticker, company name, to compare tickers output by the LLM to tickers the SEC associates with that company. The first test is- does this ticker exist in SEC data? If so, then how similar is the name in the clinical trial database to the name in the SEC data? Sometimes the names will not be similar but the ticker will still be correct, in that case, I flag them for manual review. If the ticker doesn’t exist in SEC data, it could be a de-listed company or a hallucination, either way it gets flagged for review
In my sample of 3,480 companies, I had a “needs review” rate of about 11%. LLM inference with GPT-4o cost roughly $1.50.
The most common error was assigning parent company tickets to subsidiaries (since I want to track provenance this was not what I wanted, since subsidiaries often had their own CIK’s that I wanted to track) or the false positive error of a delisted/defunct company that wasn’t in this SEC dataset. In the end, the hallucination rate was low for tickers, but this human in the loop method allowed me to keep the LLM’s role tightly scoped to what it is most suited for, and keep the rest of the pipeline deterministic. This pipeline will run daily when the database is updated with new clinical trials, and this method provides peace of mind that the data is tightly controlled and verified.
Lessons Learned #
The more I use LLMs, the more I believe that they are tools for experts and should be used sparingly. I use them to generate code I can test and for tightly controlled inference like I described in this project. While an 11% error rate doesn’t seem bad, this is a foundational data set for our research, so it is vital that all data goes through quality control, especially the data that comes from humans and LLMs.
Similar Work #
Washington University in St. Louis in collaboration with Purdue and Stony Brook University developed The Clinical Drug Experience Knowledgebase (CDEK), a comprehensive harmonization of active pharmaceutical ingredients, organizations (companies and non-commercial entities), and clinical trials through the Center for Research Innovation in Biotechnology (CRIB). CDEK is a fantastic resource and impressive harmonization effort from 2017/18 (whether the project is kept up to date is not clear, but the app is available), see their preprint and websites for more information. I have not noticed much recent activity or a release of their data pipeline so RxDataLab is developing our own data processing and harmonization schemas, with an eye towards lowering the manual curation effort required.
Interested in what we’re building? Need help exploring or structuring your data for AI applications in Biotech or pharma? Get in touch. Or subscribe for updates.
RxDataLab Research Notes
Primary-source analysis of biotech companies: clinical trials, SEC filings, and hedge fund positioning. Get notified when we publish. No fixed schedule, no filler.